
“Each individual event may be random, but the collective of events forms a law.”
— Jakob Bernoulli, Ars Conjectandi (1713)
— Jakob Bernoulli, Ars Conjectandi (1713)
1. Introduction
Machine Learning (ML) is fundamentally built upon statistical principles — particularly the Law of Large Numbers (LLN) and its lesser-known counterpart, the Law of Small Numbers (LSN).
These theories not only describe how randomness converges toward stability but also provide the mathematical foundation for how models generalize from data.
In this study, developed with OTOMATO SOFTWARE in collaboration with the Sheba Medical Center (AI Pathology Research Department, Israel) and the Population Reference Bureau (PRB), we analyze how these laws inform practical applications of ML — ranging from cancer research data processing to secure demographic analytics in cloud environments.
2. The Law of Large Numbers in Machine Learning
The Law of Large Numbers, first formulated by Jakob Bernoulli, states that as the number of observations increases, the sample mean converges to the expected value.
In the context of machine learning, this principle explains why large datasets lead to more robust and stable models: random noise diminishes, and general patterns emerge.
Example: Coin Toss Analogy
If you flip a coin 10 times, the proportion of heads might be 0.7 or 0.3 — randomness dominates.
But after 10,000 flips, the average stabilizes around 0.5.
The same happens with neural networks: as the training data grows, variance decreases, and model accuracy improves.
But after 10,000 flips, the average stabilizes around 0.5.
The same happens with neural networks: as the training data grows, variance decreases, and model accuracy improves.
Figure 1. Law of Large Numbers Visualization
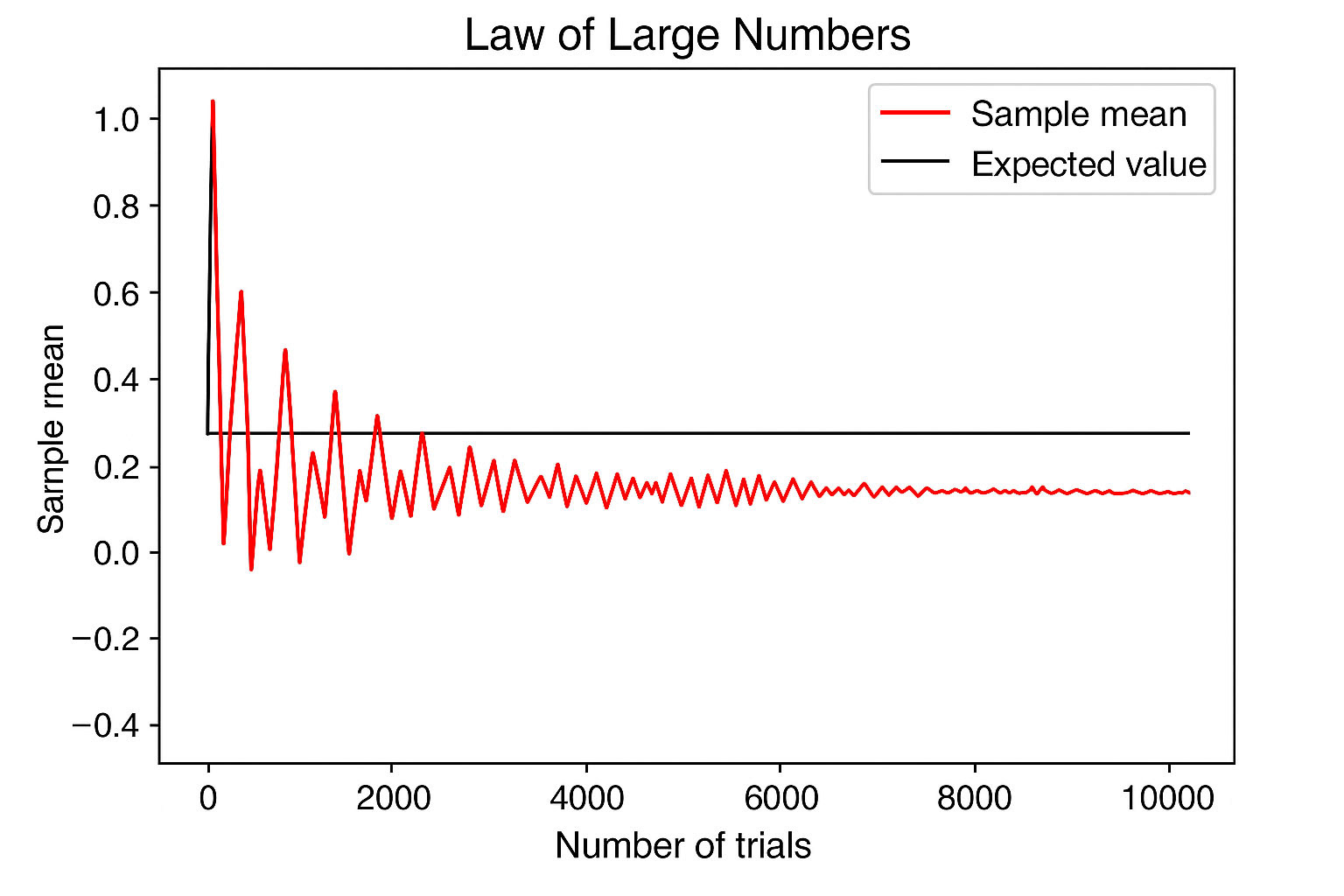
The black line approaches the expected value (red curved line) as the sample size increases.
3. The Law of Small Numbers
The Law of Small Numbers, introduced by Amos Tversky and Daniel Kahneman (1971), describes the human tendency to overgeneralize from limited samples — assuming small datasets reflect true population trends.
In Machine Learning (ML), this manifests as overfitting — when a model learns noise instead of signal, mistaking local irregularities for universal rules.
Understanding this phenomenon is essential for building resilient models, especially in sensitive domains such as healthcare or population analytics.
“People’s intuitions about randomness are deeply flawed — we expect regularity in small samples.”
— Kahneman & Tversky, 1971
— Kahneman & Tversky, 1971
4. Data Flow Architecture and Neural Cooling
Modern ML systems process vast streams of data through multi-layered architectures involving collection, cleansing, training, inference, and storage.
At large scale, this data flow behaves like a thermodynamic system — with energy, heat, and equilibrium.
At large scale, this data flow behaves like a thermodynamic system — with energy, heat, and equilibrium.
Figure 2. Data Flow Architecture
A simplified flowchart showing data ingestion, processing, model training, and cloud storage.
A simplified flowchart showing data ingestion, processing, model training, and cloud storage.
Neural Networks as Cooling Organisms
Neural networks can be metaphorically viewed as self-cooling organisms.
During training, some neurons activate intensely while others fade — a process we call demographic cooling.
Just as aging populations reach equilibrium, neural networks reach stability through pruning, dropout, and regularization.
During training, some neurons activate intensely while others fade — a process we call demographic cooling.
Just as aging populations reach equilibrium, neural networks reach stability through pruning, dropout, and regularization.
This concept bridges thermodynamics and data science, describing the transition from chaotic learning to stable generalization.
Figure 3. Cooling Neural Network Visualization
A metaphorical visualization: a “brain of data” cooling down as knowledge consolidates.
A metaphorical visualization: a “brain of data” cooling down as knowledge consolidates.
5. Cloud Security and Federated Learning
When working with sensitive medical or demographic data, as in the Sheba and PRB projects, privacy and encryption become essential.
Three core technologies define secure ML pipelines:
Federated Learning – enables training across distributed datasets without moving raw data.
Homomorphic Encryption – allows computations on encrypted data.
Zero-Knowledge Proofs – validate results without exposing inputs.
These tools make it possible to apply the Law of Large Numbers across decentralized environments — averaging without access.
Code Example: Simulated Federated Averaging
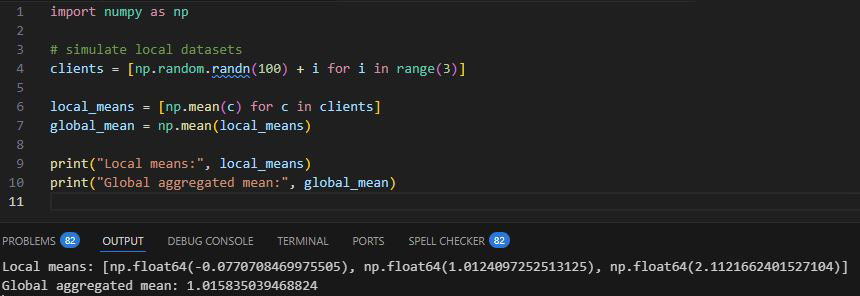
This code demonstrates the principle of aggregating knowledge without sharing raw data.
Part II — Data Architecture and Security in Machine Learning Systems
Understanding Data Streams
In modern machine learning systems, data doesn’t simply exist — it flows. Each stream — from patient genomics in oncology research to anonymized behavioral logs in cloud environments — creates a dynamic landscape of inputs.
The Law of Large Numbers (Wikipedia) ensures that as data volume grows, the system’s predictions converge to the true mean, allowing for more stable and interpretable models.
However, this stability depends on data integrity, noise management, and bias detection. The Law of Small Numbers (Tversky & Kahneman, 1971) reminds us that limited or unrepresentative samples can lead to false confidence — an especially critical problem in biomedical AI, where sample sizes are often small.
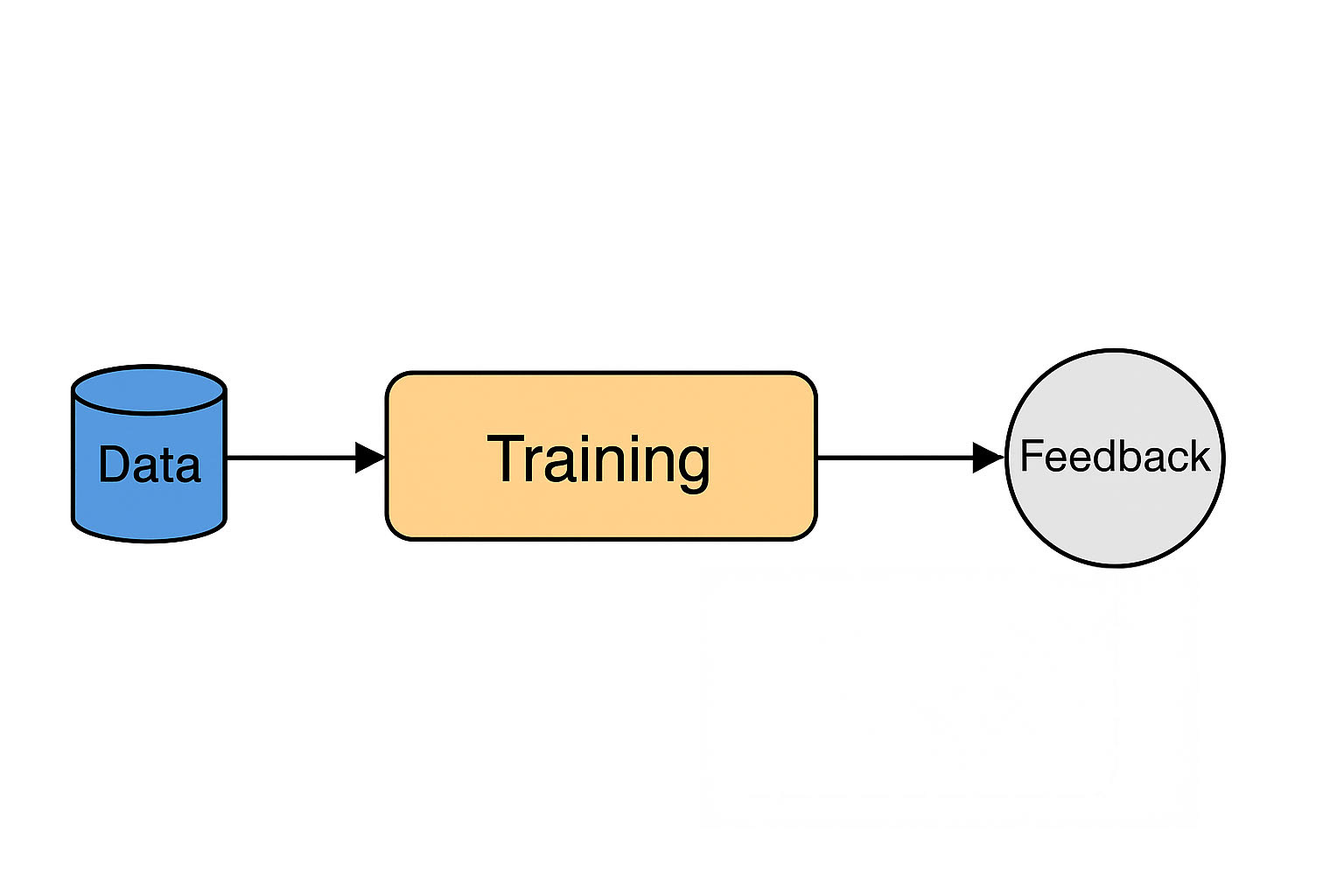
Architectural Flow
The basic machine learning pipeline — Data → Training → Prediction → Feedback — encapsulates both mathematical theory and cybersecurity challenges.
The architecture can be described in four logical layers:
The architecture can be described in four logical layers:
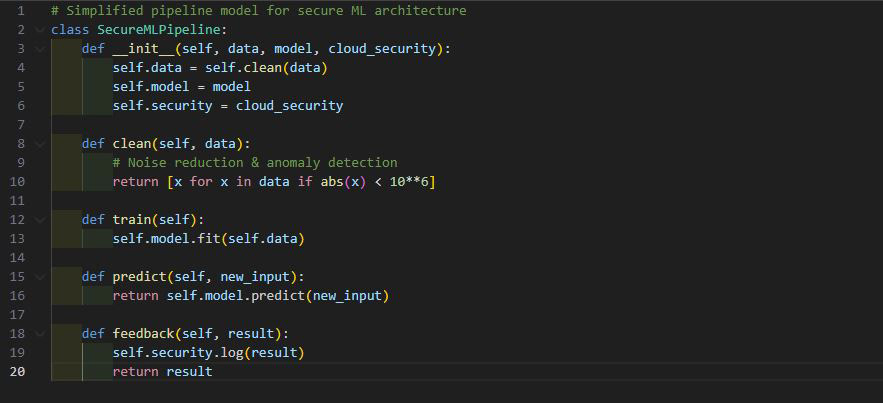
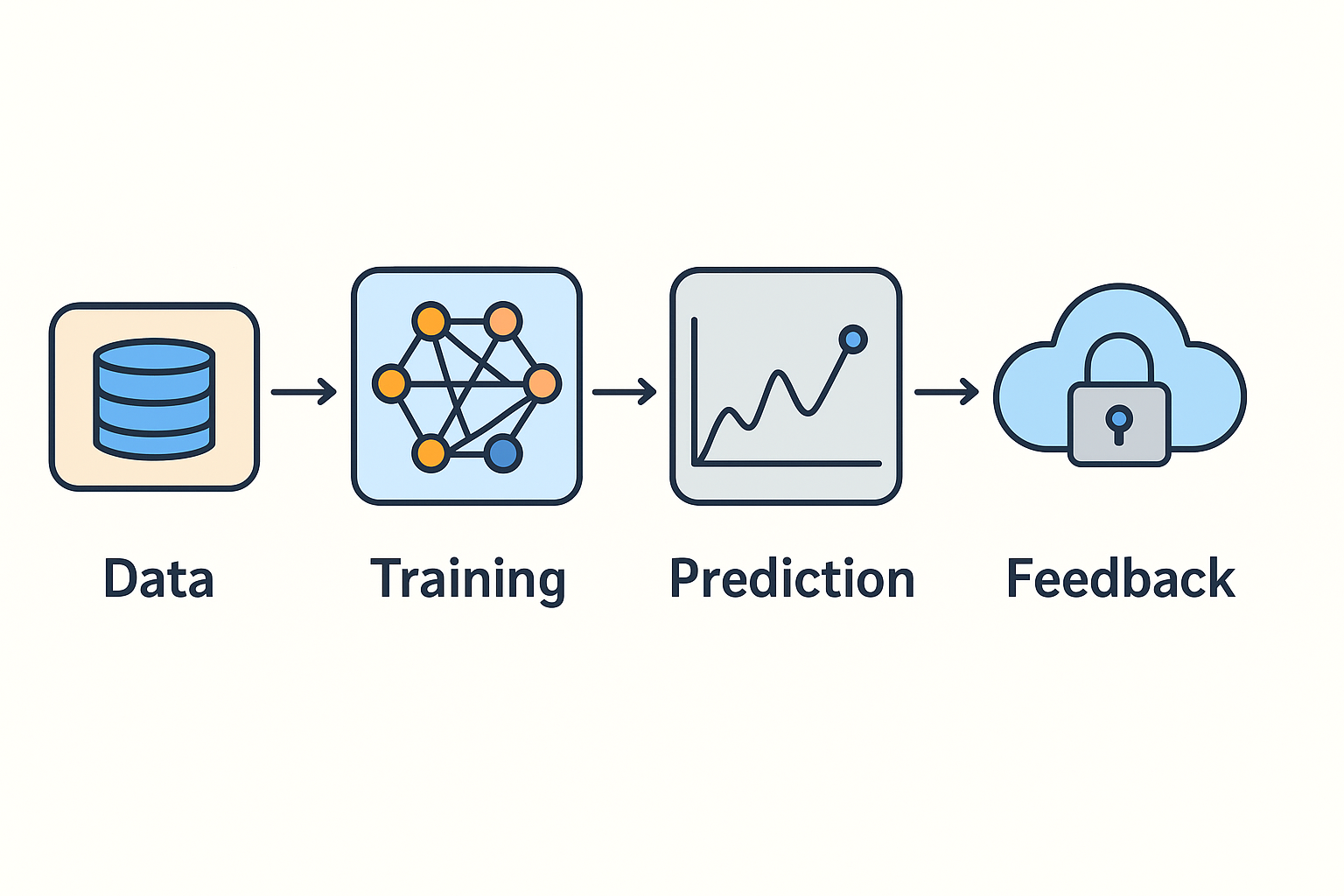
Figure 1. Cloud Protection Flow
A schematic representation of:
Cloud data encryption pipeline
Federated Learning communication loop
Secure aggregation layer where no raw records leave local nodes
Data flows through the following conceptual stages:
1. Local Data Collection
Every participating node (hospital, device, or service) keeps its raw data on-premise.
2. Local Model Computation
Each node computes gradients or statistics on encrypted datasets.
3. Secure Encryption Layer
Before transmission, results are encrypted using homomorphic encryption or secure multi-party computation.
4. Federated Aggregation in the Cloud
The central cloud only receives encrypted updates and aggregates them without decryption.
5. Global Model Distribution
The improved model is sent back to nodes, still without exposing any participant’s raw data.
This architecture ensures privacy-preserving collaboration at scale — enabling machine learning across hospitals, demographic institutions like PRB, and cloud environments without violating data confidentiality.
Figure 2. Demographic Cooling as Digital Thermodynamics
The Demographic Cooling Hypothesis suggests that neural networks naturally enter a stabilization phase, reducing their “temperature” as learning progresses.
This mirrors population dynamics: as growth slows, stability and sustainability emerge.
This mirrors population dynamics: as growth slows, stability and sustainability emerge.
In cloud-scale ML systems, this digital climate regulates energy flow, balancing data throughput, latency, and privacy constraints — forming a new kind of computational ecology.
Conclusion
The interplay between the Law of Large Numbers, demographic cooling, and secure distributed learning defines the frontier of modern AI.
Through research with OTOMATO SOFTWARE, Sheba Medical Center, and PRB, we see that the mathematical principles of probability not only underpin learning algorithms but also shape the architecture of secure, large-scale intelligent systems.
Through research with OTOMATO SOFTWARE, Sheba Medical Center, and PRB, we see that the mathematical principles of probability not only underpin learning algorithms but also shape the architecture of secure, large-scale intelligent systems.
The science of averages becomes the art of stability — in data, in systems, and in the digital populations we build.
References
Bernoulli, J. (1713). Ars Conjectandi. Basel: Thurneysen Brothers.
Kahneman, D., & Tversky, A. (1971). Belief in the Law of Small Numbers. Psychological Bulletin, 76(2), 105–110.
Anderson, C. (2008). The End of Theory: The Data Deluge Makes the Scientific Method Obsolete. Wired Magazine.
Bonawitz, K. et al. (2019). Towards Federated Learning at Scale: System Design. Proceedings of MLSys 2019.
Rivest, R., Adleman, L., & Dertouzos, M. (1978). On Data Banks and Privacy Homomorphisms. Foundations of Secure Computation.
Otomato Software | Sheba Medical Center — AI Pathology Department | Population Reference Bureau (PRB)